Staffing Automation
Designing a Resilient Staffing & Callout Automation Platform for reliable staffing at scale across distributed regions.
Snapshot
This project demonstrates how layered automation, human-in-the-loop design, and operational prioritization can transform manual workflows into resilient, scalable systems. The goal was not theoretical optimization, but real-world reliability.
Problem: Manual staffing processes struggled to scale, creating high operational overhead, recurring coverage risk, and material inefficiencies.
Solution: A layered staffing system combining algorithmic initial placements, modular weekly re-staffing, and integrated callout handling within a staff-facing app.
Impact:
Reduced time spent staffing by over 70%
Significantly improved coverage reliability across distributed regions
Generated material annual cost and inventory savings
Note: This case study is based on a real system I designed and built. All details have been generalized to preserve confidentiality.
Context
I worked on staffing systems supporting a large, distributed workforce organization operating across multiple regions. Each week required placing team members across hundreds of schedules while accounting for frequent last-minute changes, differing training requirements, and regional constraints.
As the organization scaled, staffing reliability became increasingly difficult to maintain through manual coordination alone.
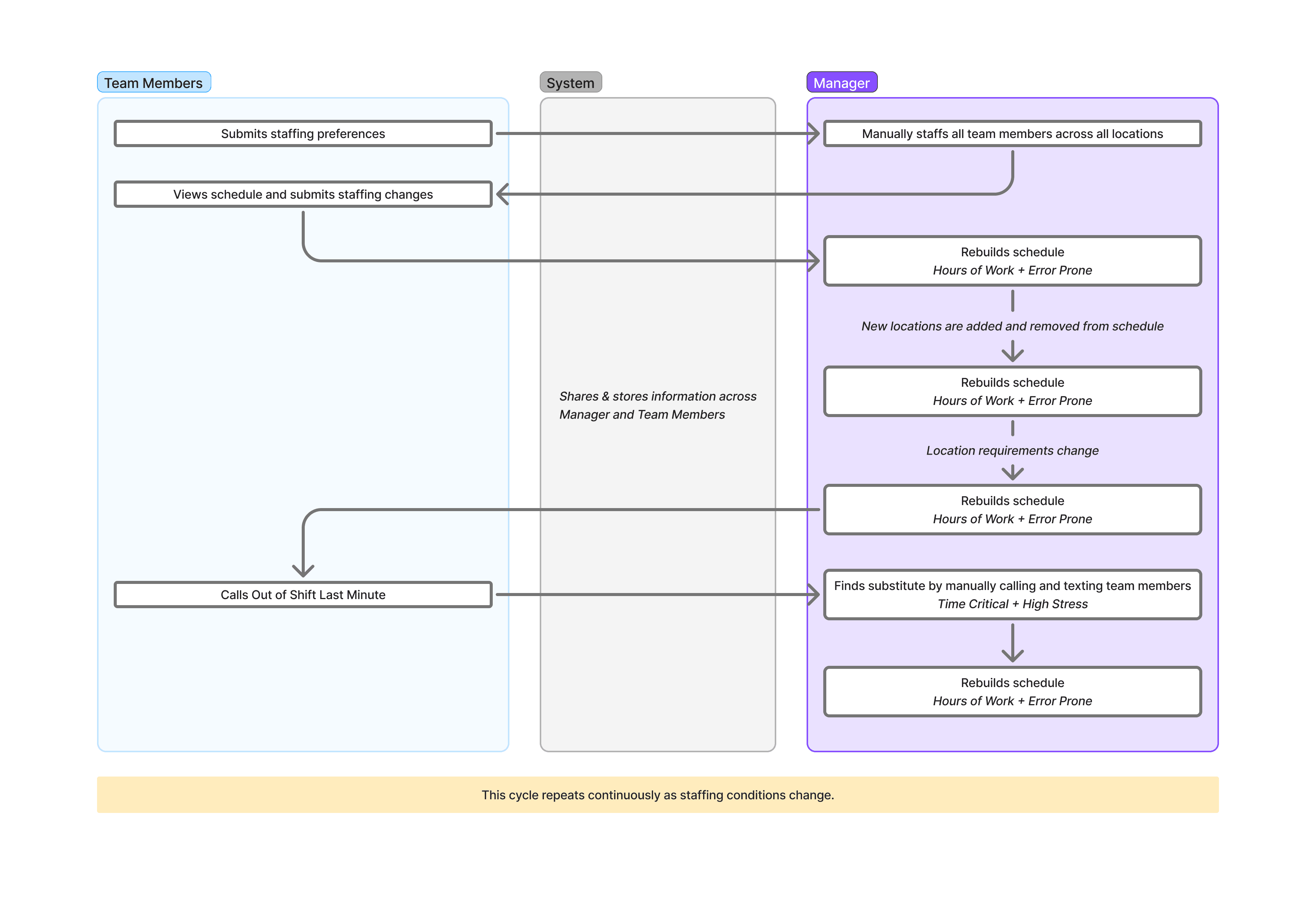
Problem
Staffing was brittle and manual. Coverage gaps, frequent callouts, training requirements, and inventory constraints made reliable staffing at scale difficult without heavy operational effort.
What I built
I designed and built this platform end-to-end, owning all major components: system architecture, algorithm design, core production code, and operational rollout into live operations.
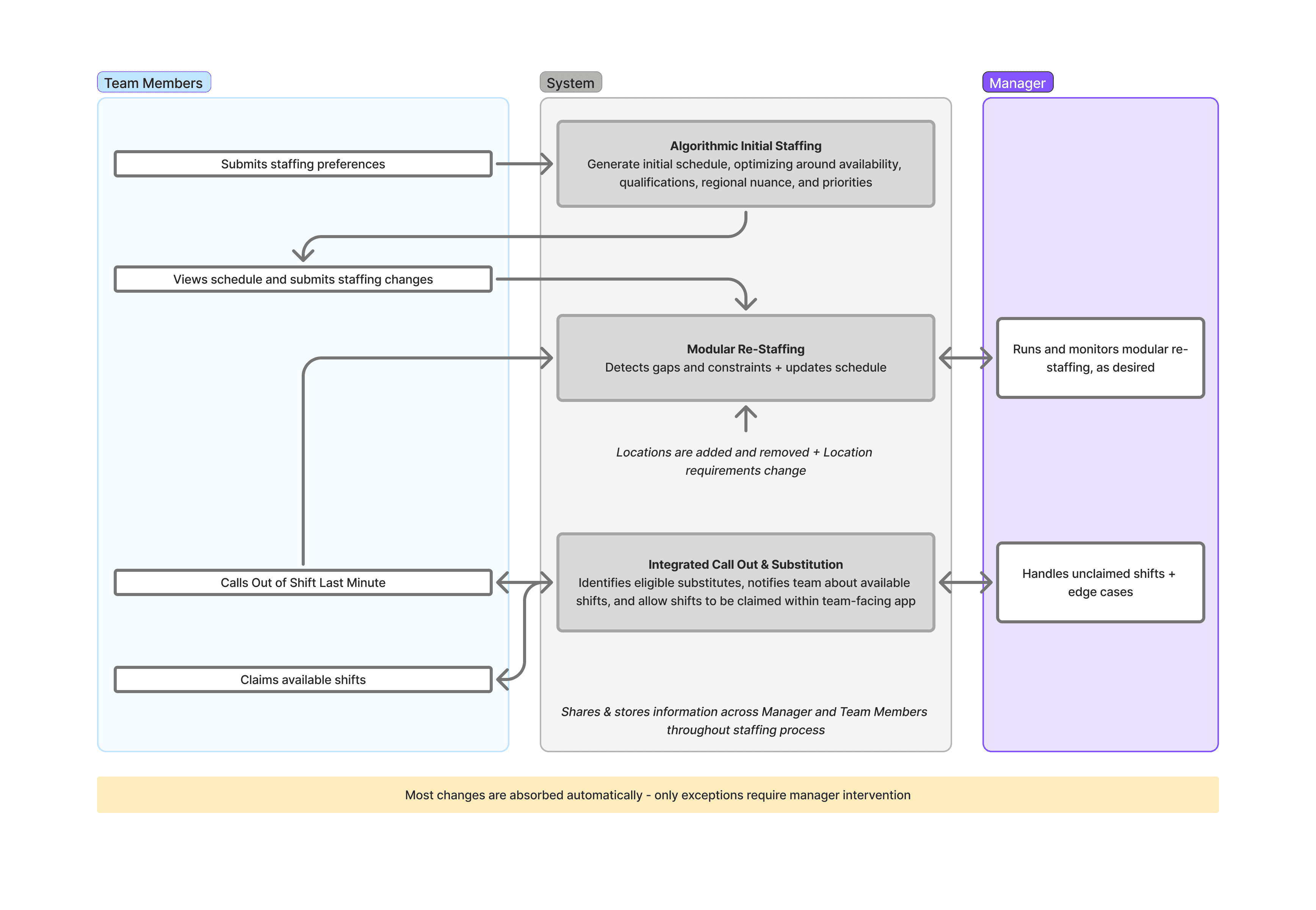
The system was composed of three primary layers:
Algorithmic Initial Staffing - The primary staffing engine that matches staff to schedules using availability, qualifications, regional rules, and operational priorities.
Modular Re-Staffing - Weekly restaffing system that removes unavailable staff members, fills gaps, and incorporates new team members for training, while preserving stability where possible
Integrated Callout & Substitution Experience - A staff-facing app that centralizes schedules, availability, callouts, and shift claiming, alongside the contextual information needed to claim an available shift, reducing last-minute coordination and increasing response speed during coverage incidents
Key decisions & tradeoffs
Rather than attempting a single “perfect” optimization, the system makes decisions in deliberate layers, reflecting real operational constraints.
Design Priorities
Coverage first - ensure all sessions are staffed before optimizing secondary goals
Urgency awareness - prioritize near-term reliability over distant planning
Operational efficiency - reduce downstream costs and coordination burden
Quality alignment - scale instructional quality alongside volume
Stability - preserve continuity and minimize unnecessary disruption
Design philosophies
Firefighting first - The system is optimized to reliably solve the next few weeks rather than generate a brittle long-term plan. This acknowledges that staffing inputs change continuously and favors resilience over theoretical optimality
Modular re-staffing - Automation was applied where it reduced cognitive load, not where it removed human judgment. Operators retained control over sensitive decisions, which increased trust and adoption
Stability over churn - In-semester changes favored conservative updates rather than aggressive reshuffling. True optimization occurred during initial planning, while ongoing changes prioritized continuity.
Outcome
The platform was adopted as a core operational system, dramatically reducing ongoing staffing effort while improving reliability across regions. By incorporating operational and material considerations directly into staffing decisions, it also meaningfully reduced resource requirements and associated costs.
Most importantly, the system enabled the organization to scale its footprint without a proportional increase in operational complexity or failure modes
Key learnings
In dynamic, human-driven operations, resilient systems that prioritize stability and incremental fixes outperform brittle attempts at perfect optimization.
Operational nuance that seems “too human to automate” can often be handled safely by separating stable core rules from explicit, structured exception layers.
More